How LLM Actually Works
Millions of people use tools like ChatGPT, Claude, or Grok daily, without knowing how this LLM magic actually works. This article breaks down that process step by step.
Sahidur Rahman
4/23/202611 min read

The release of ChatGPT on November 30, 2022, marked a pivotal moment, immediately capturing the attention of millions who were captivated by its seemingly human-like intelligence in generating text. Initially, this groundbreaking model's capabilities were focused primarily on producing cohesive essays, generating functional code snippets, and engaging in natural, conversational dialogue. It was, however, limited in scope, lacking support for multimodal inputs like images, voice, or robust file handling. Furthermore, early iterations were prone to generating factual errors, a phenomenon commonly referred to as "hallucinations," which we will delve into in more detail later. Since that initial launch, the technology has undergone a rapid and significant evolution. ChatGPT and similar models have made massive strides in supporting multimodal communication—integrating voice commands, processing and generating images, and handling various file types and video data. This progression has transformed these tools from specialized text generators into a general purpose AI assistant platform.
Today, millions of individuals across the globe rely on cutting-edge LLMs such as OpenAI's ChatGPT, Anthropic's Claude, or Elon Musk's Grok. The responses received from these platforms are often so fluid and contextually relevant that they appear strikingly human. Yet, despite this sophisticated output, most users are fundamentally unaware of the underlying mechanism. The model does not formulate a complete, coherent response in a single step, nor does it even "know" what its next word will be in a human sense.
Instead, the process is inherently iterative and probabilistic. The AI constructs its answer incrementally, building it word-by-word or, more precisely, token-by-token. For every single piece of output—be it a word, a punctuation mark, or part of a complex phrase—the model performs a probabilistic selection from an enormous vocabulary of potential options, which can often exceed 100,000 distinct tokens. This process, driven by complex statistical patterns learned during training, determines the highest probability next token to generate.
In the following detailed article, we will provide a comprehensive, step-by-step breakdown of this entire process. We will trace the journey from the moment a user hits the "send" button on their query to the final, complete text appearing on the screen. We will explain exactly how these powerful Large Language Models actually function and achieve their remarkable outputs.
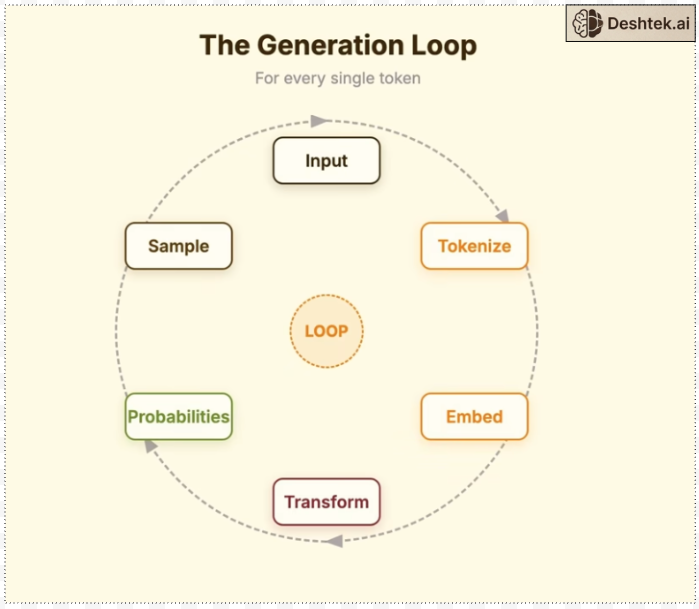
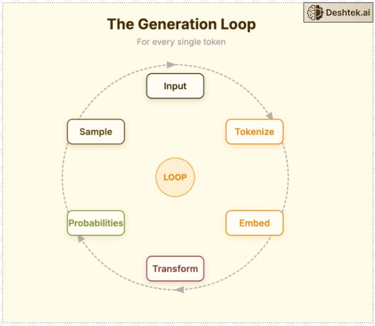
The entire process of an LLM responding to your query can be broken down into five major, sequential stages that are initiated the moment you type a text-based prompt and hit the 'enter' or 'submit' key. These stages involve tokenization, embedding, the attention mechanism, the probabilities, sampling and finally, the output generation.
Tokenization: Your text becomes pieces.
Embedding: Those pieces become meaningful vectors.
Transformer: Those vector texts are processed through attention.
Probabilities: Every possible next text gets a probability score.
Sample: One text is selected and it continues the loop for next token
Let’s look at each step in a bit more detail.
Step 1: Tokenization
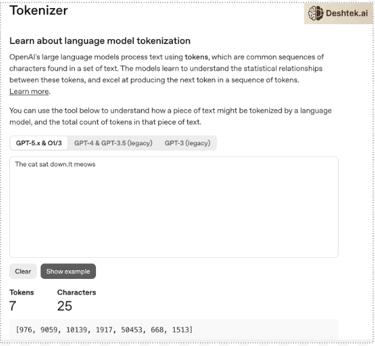
LLMs don’t read words, they read tokens. Here is the OpenAI Tokenizer. I typed “The cat sat down. It meows” and I get 7 tokens.
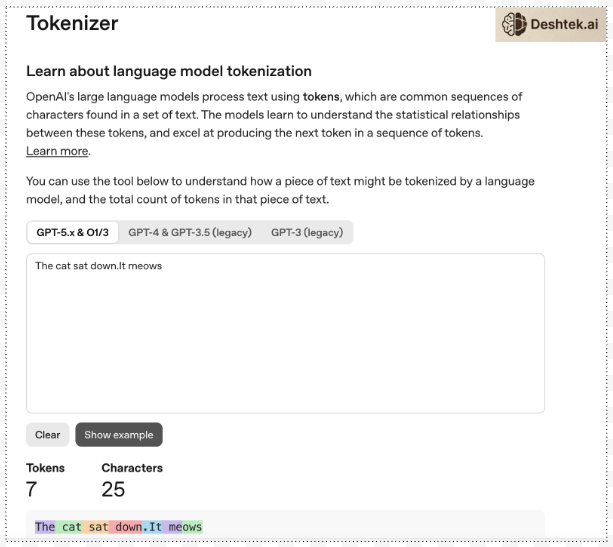
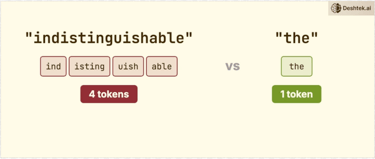
Notice most tokens are for the words but there are separate tokens for the period. This isn't random. Tokenizers are trained on text data to find efficient patterns. This happens before the model ever sees your input. It's a pre-processing step not the neural network deciding how to split common words like 'the' gets one token. Uncommon or long words get broken into subword pieces. So the word “indistinguishable” that's four tokens and “the” is one token.
Tokenization is the crucial pre-processing step that occurs before an LLM receives your input.
Key points about tokenization:
Efficiency: Common words (e.g., 'the') often become a single token, while uncommon or long words (e.g., 'indistinguishable') are split into multiple subword tokens. Punctuation, like a period, also gets its own token.
API Limits: This is why an API's token limit (e.g., 4,000 tokens) is not the same as a word count. For English, 4,000 tokens translates to roughly 3,000 words.
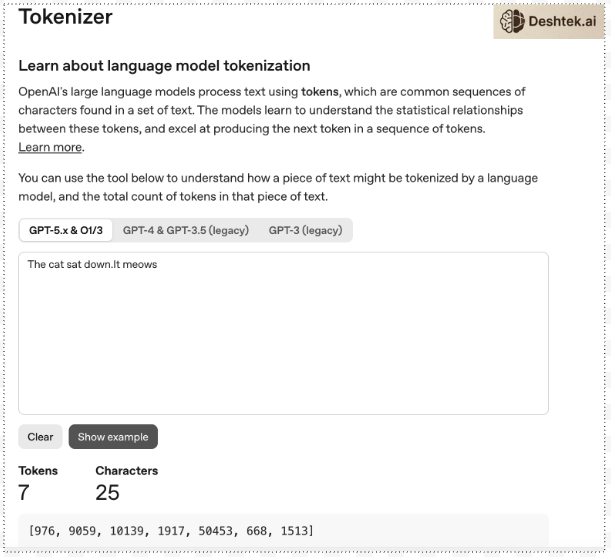
Conversion to Numbers: Each token is assigned a unique number, called a token ID. The input text is transformed into a sequence of these integers (e.g., “The cat sat down. It meows” becomes a sequence of seven numbers).
Next Step: This numerical sequence is what enters the model. However, these raw numbers lack semantic meaning, which is addressed in the next step: embeddings.
Step 2: Embedding
Tokens are smaller units of the entire sentence. Every token gets a number also known as token ID. So “The cat sat down. It meows” becomes a sequence of seven numbers.
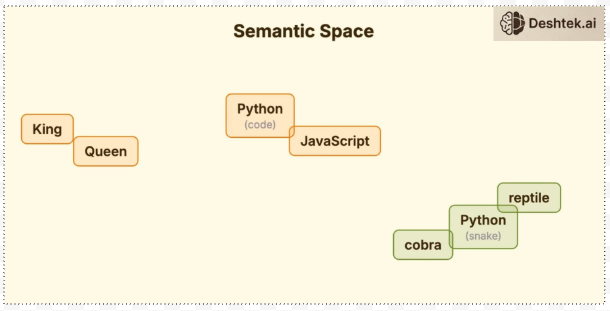
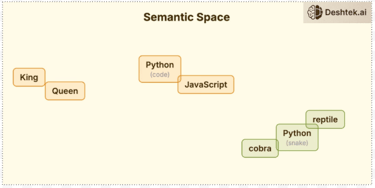
But numbers alone don't carry meaning. That step is embedding. The model needs to understand what the token ID means. So every token ID gets converted into a vector, a list of numbers representing its meaning. These vectors have thousands of dimensions. GPT3 uses over 12,000 numbers per token and these aren't random numbers, they're coordinates in a meaning space. Think about vectors as words with similar meanings that end up near each other. For example, the word “King” is near “queen”. “Python” the language is near “JavaScript”. “Python” the snake is somewhere completely different that sits with “cobra”.
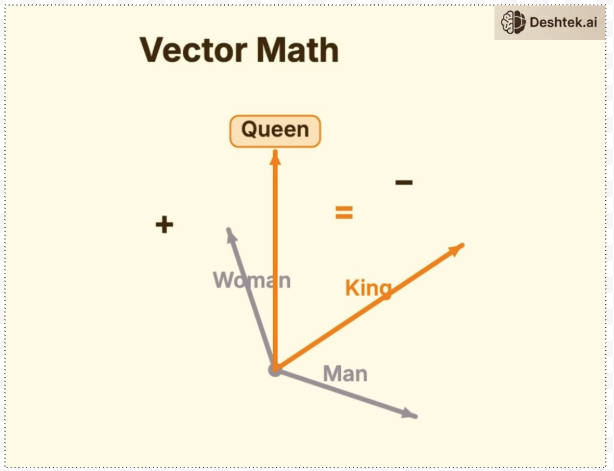
Once words/token IDs are in a vector, you can easily perform vector math to understand the meaning of a word. For example if you take the word “king” subtract it from “man” and add “woman” you get “queen” conceptually.
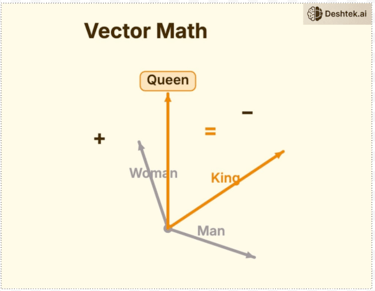
This is how the model understands that JavaScript and Python are related, not because anyone told it but because they appear in similar contexts. These rich vectors now flow into the next step transformer.
Step 3: Transformer
The transformer phase is the core engine of modern Large Language Models (LLMs), the central to this transformer phase is a concept called Attention. To understand the concept of Attention, imagine a highly skilled spotlight operator at a concert. As the music evolves, the operator doesn't just keep the light in one fixed position; they dynamically decide which musician to highlight. During a guitar solo, the spotlight focuses intensely on the guitarist. When the vocalist steps forward, the light shifts to the singer. Attention works in a fundamentally similar way for an LLM. When the model processes any given token in an input sequence (a word, a sub-word, or a character), it doesn't treat all other tokens in the sentences equally. Instead, it calculates a score—an attention weight—to determine which of the other tokens in the sequence are most relevant or informative for understanding the current token's meaning in context. Consider the example “The cat sat down. It meows”. A human reader instantly understands that "it" refers to "The cat”. When the model processes the token "it," the attention mechanism is activated. It assigns a high attention weight to the token "cat" and a low attention weight to the other tokens. The model has learned, through training on a vast array of text, that the property of “meow” is typically associated with the subject of the action ("cat"), which is an animal. This ability to connect distant but semantically relevant parts of a sentence is a massive leap over previous models.
What ultimately emerges from the transformer layers is not just a simple sequence of words, but powerful vectors (mathematical lists of numbers). These vectors encode not merely the individual meaning of each token (like a simple look-up table), but a rich contextual information about how that token relates to every other token in the entire input sequence. This contextualized vector representation is what the model uses for the final steps of predicting the next token Probability, enabling it to generate coherent, contextually appropriate, and human-like text.


Step 4: Probability
The core function of the transformer architecture, after processing the input sequence, is to determine the most statistically probable next element—the subsequent token. This is the generative step. The final layer of the Language Model (LLM) does not immediately select the next word. Instead, it executes a crucial intermediate step: it produces a score (often called a logit) for every single token present in its entire vocabulary. If the vocabulary size is, for instance, 50,000 unique tokens, the model will output 50,000 corresponding scores.
These raw scores are then normalized and transformed, typically using a softmax function, to convert them into a probability distribution over the entire vocabulary. This distribution is the model's actual output—it's a set of probabilities that collectively sum up to 100%, indicating the likelihood of each token being the correct successor.
For a concrete example, consider the input prompt: “The cat sat down. It meows,” which might be used to prompt a model to complete a story. Or, for a more direct completion task, if the input is truncated to “The cat sat….” The model’s internal mechanism calculates the probability for every possible next word. To decide on the word "down" as the next token, the model might assign it a probability of 45%. Simultaneously, it might assign the word "on" a probability of 38%, "by" a 10% probability, and the remaining 7% distributed across thousands of other less likely tokens (such as "banana," "quantum," or "slept").
The model’s role is strictly probabilistic. It doesn't "know" or "think" about what to say; it merely calculates the conditional probability of the next token given the preceding sequence. The actual final decision of which token to select from this distribution is handled by a separate decoding strategy (such as greedy search, beam search, or nucleus sampling), which uses these probabilities to select the final output token and thus generate the complete text.


Now, out of these enormous possibilities and their corresponding probabilities—calculated after the crucial steps of tokenization, embedding, and passing through the Transformer architecture—how does the Large Language Model (LLM) actually select the subsequent token or word? The initial, intuitive thought might be to simply employ a greedy approach: always select the token with the absolute highest calculated probability. If the probability distribution suggests 'down' has a 0.9 probability, and 'on' has a 0.05 probability, then we just pick 'down' and move on. However, the process is not that straightforward, nor is it desirable for generating human-like, creative, and varied text. This is where the final, critical step of Sampling comes into play.
Step 4: Sampling
Sampling is the mechanism that translates the raw probability distribution generated by the LLM into the actual chosen word. It introduces an element of controlled randomness (stochasticity) to prevent the model from getting stuck in repetitive, highly predictable, or dull sequences of text. Different sampling techniques exist, each striking a balance between coherence (sticking to high-probability words) and creativity (allowing some lower-probability, unexpected words):
Greedy Search (The Baseline): As mentioned, this simply picks the token with the maximum probability. While it's efficient and often used in tasks like machine translation where correctness is paramount, it frequently leads to repetitive, generic, and locally optimal but globally poor text.
Random Sampling: This technique treats the output probabilities as a literal lottery ticket. It samples the next token based directly on its probability distribution. While it introduces variance, it can often lead to nonsensical output because low-probability, irrelevant words might occasionally be chosen.
Top-K Sampling: This is a vast improvement. Instead of considering the entire vocabulary, the model first restricts the set of possible next tokens to the K tokens with the highest probability. It then performs random sampling only within this reduced set of K tokens. A larger K leads to more variety, while a smaller K ensures the model stays relevant.
Nucleus Sampling (Top-P Sampling): Currently one of the most popular and effective methods, Top-P sampling is more dynamic than Top-K. Instead of fixing the number of tokens (K), it selects the smallest set of tokens whose cumulative probability exceeds a threshold P. If P=0.9, the model will consider just enough high-probability tokens to account for 90% of the total probability mass, regardless of how many tokens that takes. This adapts well to different contexts; in highly constrained contexts, the nucleus might be very small, and in open-ended contexts, it might be larger.
The choice of sampling strategy and its parameters (like K or P) is crucial, fundamentally determining the style, creativity, and coherence of the text generated by the LLM. Here, you have control to choose the type of answers you want, balancing creativity with your specific purpose. That's where the concept of temperature comes in. Temperature is a crucial hyperparameter in Large Language Models (LLMs) that adjusts how confident the distribution of possible next tokens is, effectively controlling the randomness and creativity of the model's output.
When an LLM generates text, it calculates a probability distribution over the entire vocabulary for the next word or token. A higher temperature (e.g., 0.8 to 1.0) flattens this distribution, making lower-probability tokens more likely to be selected. This results in more varied, creative, and sometimes surprising or "hallucinated" outputs. Conversely, a lower temperature (e.g., 0.1 to 0.5) sharpens the distribution, increasing the likelihood of selecting the most probable token. This leads to more deterministic, focused, and predictable responses, which is often preferred for tasks like summarization, factual QA, or code generation where accuracy and consistency are paramount.
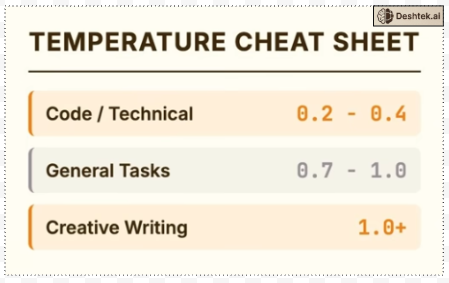
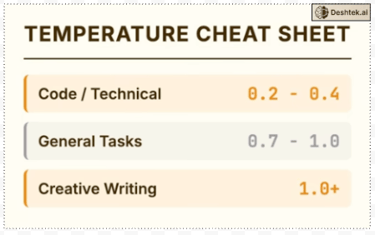
The temperature parameter allows users to fine-tune the trade-off between coherence and diversity in the generated text, making it a powerful tool for controlling the output style. For example if you are using LLM to generate code, you want
Quick reference writing code temperature 0.2 to 0.4, you want precision. General tasks temperature 0.7 to 1.0 balanced. Creative writing temperature 1.0 or higher embrace variation.
When you set these parameters in an API call you're directly shaping this selection process. One token selected is great but we've only generated one token. The last piece is the Loop.
Step 5: Loop
We selected the word “down” based on probability, now we append it to the input and run the entire process again Tokenize > Embed >Transform > Probabilities > Sample for every single word to complete the sentences.
Final Thought:
Here are three immediate takeaways about LLMs:
Hallucination is not Lying; It's Pattern Matching. When an LLM "hallucinates," it is generating text that perfectly matches the pattern of a confident, factual-sounding response. The underlying probability distribution can't distinguish between truth and plausibility. Implication: Always independently verify any factual claim made by an LLM, especially when the response seems highly confident.
Temperature Controls Randomness, Not Creativity. Increasing the temperature setting doesn't make an LLM more creative; it simply increases the likelihood of selecting tokens with lower probability. What humans interpret as "creativity" is a result of this introduced randomness.
Context Limits are a Computational Constraint. Context limits are not arbitrary business decisions; they are a direct reflection of the LLM's architectural constraints.


Contact us
Whether you have a request, a query, or want to work with us, use the form below to get in touch with our team.


Location
19271 Bridle Path,
Hamel, MN 55340 , USA
Hours
I-V 9:00-18:00
VI - VII Closed
Contacts

Desktek.ai© 2026 Deshtek Inc.